Introduction to web scraping with python
Published on: 2020-09-03
1. Jak začít ….
Nejlepší je si vymyslet projekt, pro který by se vám web scraping hodil. Mě se třeba líbí testovat si různé online magazíny jako neviditelnýpes.cz, irozhlas.cz nebo aeronet. Ale můžete si udělat třeba hlídač cen.
Vybrat si webovou stránku, která vás zajímá. Stránka by neměla mít pro začátek moc javascriptu, protože scrapovat javascript je složitější než čisty kód html. Čím více je stránka html, tím lepší pro první web scraping.
Výběr technologie pro začátek doporučuji třeba knihovny -
requests+beautiful soup. Nejčastěji doporučovaná kombinace pro začátečníky.Zkusit si udělat nějakou analýzu nad staženými daty pomocí python knihovny
pandas. Nebo script, který pomocícrontabbude stahovat a ukládat data měnící se v čase.
2. Python nástroje pro web scraping
Pro web scrap jsou nejznámější technologie Selenium, Beutiful Soup a Scrapy.
Selenium- je framework pro testování webových aplikací. Funguje na principu otevři prohlížeč zadej do něj URL a zkoušej různě vyplňovat dotazník či formulář. Selenium vidí pouze to co vidíte vy v prohlížeči. Hodí se na práci s Javascriptem.Beautiful Soup- jedná se o knihovnu, kterou je do pythonu nutné doinstalovat. V současné chvíli se používá beautifulsoup4. Tato knihovna je schopna z kódu HTML vytáhnout potřebné informace. Bohužel nedokáže sama poslat požadavek na server. Musíme tedy pro posílání požadavků využít jiných knhoven například requests. Po získání HTML dané stránky je nutno ještě parsovat kód pomocí parserů v beautifulsoup4. Následně vlastně procházíme čistý text (string) HTML kódu a podle HTML tagů a jinýc h v něm hledáme potřebné informace. Tato knihovna je vhodná po snadné úlohy, které se zaměřují na scrap jednoho indexu webové stránky. Ne že by nebylo možné procházet více stránek, ale pro procházení více stránek je třeba si logiku napsat sám manuálně. Tato knihovna se pro začátečníky doporučuje. Jedná se snadnou knihovnu, která má docela pěkně napsanou dokumentaci. Pokud se chcete zabývát web scrapingu doporučuji začít touto knihovnou a různě si zkoušet. Pomocí bs4 jste schopni rychle dosáhnout poměrně pěkných výsledků, které vás budou motivovat do další práce. Komunita je docela velká a projektu se aktivně věnuje. Knihovna je docela pomalá, ale na nazačátek nebo malý scrap to vůbec nevadí.Scrapy- opensource framework. Jedná se o kanón na web scraping pomocí, kterého jste schopni dělat scrap a crawl na vysoké úrovni. Framework je také přenositelný a je možné použití na Linux, iOS nebo Windows. Je velmi rychlý až 20x rychlejší než jiné nástroje. Framework se používá už na profesionální a plnohodnotný scrap. Je schopen posílat několik requestů najednou a probublávat stránkou skrz naskrz. Bohužel pro začátečníky není úplně nejvhodnější, protože jeho dokumentace je složitější a také vytvářené objekty pro scrap jsou poměrně už vyšší python. Sám jsem ze scrapy ze začátku dost zmatený jako začátečník. Daleko lépe se mi orientuje v Beautiful soup. Na velký komplexní projekt je jednoznačná volba Scrapy.
Jednoduché shrnutí:
- Na Javascript - Selenium
- Velký komplexní projekt, který má být snadno přenositelný a rychlý - Scrapy
- Jste začátečník v pythonu nebo ve scrapu - Beautiful Soup
3. Scrap vs Crawl
Mám docela chaos o tom co znamená scrap a crawl. Na internetu se používají oba pojmy a většinou nejsou vysvětleny. Někdy je míchají dohromady jindy používají jen jeden nich. Vyznat se v nich může být matoucí, protože oba pojmy spolu velmi úzce souvisí. Tak jak to je ?
scrap:
Anglicky to scrape znamená škrábat nebo seškrábnout. Scrap je definován jako škrábání informací strojovým způsobem z webových stránek. Jelikož data a informace můžete pouze prohlížet web scrap je způsob, jak získat data ze stránek fyzicky a uložit si je do databáze a dále nad nimi provést nějakou analýzu pomocí knihovny pandas. Tedy stahujeme konkrétní data, které potřebujeme.
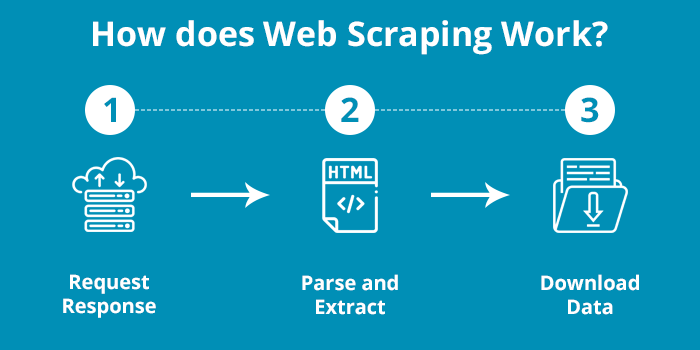
Scrap se skládá ze těchto kroků:
- request-response
- parse and extract - parsování znamená převzít kód hmtl (markup language s jednoduchou strukturou) a přenést ho do obyčejného textu, který je počítač schopen zpracovat. Data extrahujeme pomocí regulárních výrazů (regex) hledání speciálních tagů apod.
- stažení dat - ve formátě JSON, CSV nebo do databáze.
crawl:
Anglicky to crawl znamená plazit se. Používá se to ve spojení plazení pavouka (spider crawling). Jedná se o procházení a indexování stránek. Crawling dělají služby jako Google, Yahoo apod. Děláte víceméně to co vyhledávače. Mohli bychom takový program nazvat třeba také searchbot, searchengine. Hledáte různé stránky na webu a indexujete je. Následně si je ukládáte všechny dostupné cesty a zákoutí do databáze. Z toho pak vidíte všechny možné cesty odkud můžete scrapovat data na daném webu.
- Select a starting seed URL or URLs
- Add it to the frontier
- Now pick the URL from the frontier
- Fetch the web-page corresponding to that URL
- Parse that web-page to find new URL links
- Add all the newly found URLs into the frontier
- Go to step 3 and reiterate till the frontier is empty
Scrap vs Crawl shrnutí:
Jednoduše to zatím chápu tak, že crawlujete stránky, z kterých postupně jak je crawlujete scrapujete data, které potřebuje. Tedy procházím stránku po stránce a vždy si na každé stránce stáhnu informace, které potřebuji.
4. Je to vůbec legální ?
Před začátkem práce by si měl každý uvědomit, zda ho jeho činnost nemůže dostat do kriminálu. Uvedu zde několik bodů, které jsem našel, aby scrapování bylo zcela OK. Když se zamyslíme, tak scrap není nic jiného než procházení stránek a stahování informací strojovou metodou. Když manuálně procházíte webové stránky děláte vlastně přesně to samé akorát mnohem mnohem pomaleji. Když byste stránky procházeli přes webový prohlížeč a nalezené informace byste si psali na papír tak je postup naprosto stejný. Ovšem rozdíl nastává v oné zmíněné rychlosti a také v tom, jak následně s těmito daty naložíte. Ne všechna data se mohou automaticky zveřejňovat dále, jelikož spadají například pod autorské práva. Některé stránky mají přímo ve svých pdomínkách napsáno, že zakazují použití crawl/scrap/harveting strojovou metodou. Tedy i když děláte to samé jako prohlížeč a manuálně tak pro mnoho společností to není to samé. “Terms of Service (ToS) often prohibit automatic data collection, for any purpose”[1]. Takže když si dají do podmínek, že je zakázáno sbírat data strojově tak Váš postup bude nelegální i když vlastně procházíte stránku jako byste ji procházeli manuálně. Uvědomte si, že i zde platí zákon o soukromém vlastnictví a všchny stránky někomu patří a ten si může nstavit, jak bude s jeho soukromým vlastnictvím nakládáno. Pokud nebudete dodržovat podmínky vlastníka těchto informací říkaté si o problém.
Základní pravidla legálního scrapingu:
- API - Pokud daná služba poskytuje pro Vaše účely API (data, které potřebujete získat poskytují například ve formátu JSON skrze API) měli byste využít toto API. Například kurzovní lístek z ČNB je nabízen formou API v .txt souboru. V takovém případě tedy nebudu scrapovat celou stránku (rozumněj HTML kód) ČNB abych kurzy získal, ale využiji jejich API.
- Frekvence požadvků - Je nutné, aby jste ve svém skriptu měli nastavenou frekvenci stahování a procházení tak, aby jste neshazovali server - nadměrně nezatěžovali server požadavky. Ono nadměrným posíláním požadavků nemusíte rovnou shodit server, ale můžete jej zpomalovat pro další uživatelé. Shozením serveru nebo zpomalováním můžete poškodit značku nebo stránky a tuto škodu po Vás může potom někdo chtít nahradit. Myslím, že třeba scrapy tohle řeší už za vás. Neúměrné stahování dat a dokonce shození serveru je tedy také trestné. Doporučená frekvence je 1 požadavek (request) za 10-15s. Pokud budete používat toto pravidlo neměli byste způsobit žádné peklo - mělo by to vypadat jako klasické manuální procházení stránek na které jso uweby stavěny.
- Autorské práva či ostatní práva vztahující se na data - Zkontrolujte jaká autorská práva či jiná práva se vztahují na data, které si chcete stahovat. Zda se nejedná o soukromé data. Stahování dat s autorskými právy a jejich další komerční využití je neetické a nelegální.
- Veřejné data - Zpracování veřejně dostupných dat by mělo být zcela OK. Ovšem mějte na paměti, že i toto může zcela změnit Terms of Service a i veřejně dostupné data nemusí být k použití.
- robots.txt - Provádějte scraping v souladu s pravidly, které naleznete v souboru robots.txt. Jedná se o soubor, který dá k dispozici webová stránka a popisuje v něm, jak má být Váš robot nastaven, aby jste mohli danou stránku crawlovat a scrapovat. V souboru může být taky uvedeno, že na stránku nesmíte žádného robota použít. Pokud nebudete dodržovat podmínky uvedené v tomto souboru vystavujete se riziku soudního sporu. Níže naleznete jaké informace můžete v takovém robotovi nalézt.
- ToS Terms of Service - podobně jako robot.txt fungují také všeobecné podmínky, smluvní podmínky nebo podmínky (pravidla) pro používání webové stránky, které je také dobré si přečíst než začnete pracovat na web scrapingu. A dodržovat je. Většinou je naleznete jako odkaz někde úplně dole na hlavní stránce. Jako příklad může posloužit portátl irozhlas.cz, kde úplně dole naleznete link Podmínky užití - Podmínky užití obsahu Českého rozhlasu
Nejpodstatnější je co se s staženými daty budete dělat a jaký způsobem budete data získávat. Pokud budete data používat pouze pro své účely a nebudete je šířit na internetu nebo používát pro komerční účely, tak byste měli být OK. V opačném případě je dobré zkontrolovat zda k tomu máte oprávnění. Ono i když budete dodržovat robots.txt, ale nebudete dodržovat ToS, tak jste zase v průseru, ovšem stránka, která v ToS zakazuje strojové procházení. Ovšem procházení může být zakázáno i v robots.txt je nutné číst obojí. A hlavně nezapomínejte na důležitou věc logika, pravda nebo férovost nemá s právem nic společného. Právo závisí také dost na interpretaci lidí a kvalitě Vašeho právníka. Rozhodně nedoporučuji se hájit sám v prípadě právní pře.
Jak postupovat
Use an API if one is provided, instead of scraping data.
Respect the Terms of Service (ToS).
Respect the rules of robots.txt.
Use a reasonable crawl rate, i.e. don’t bombard the site with requests. Respect the crawl-delay setting provided in robots.txt; if there’s none, use a conservative crawl rate (e.g. 1 request per 10-15 seconds).
Identify your web scraper or crawler with a legitimate user agent string. Create a page that explains what you’re doing and why, and link back to the page in your user agent string (e.g. ‘MY-BOT (https://yoursite.com/mybot.html)’)
If ToS or robots.txt prevent you from crawling or scraping, ask a written permission to the owner of the site, prior to doing anything else.
Don’t republish your crawled or scraped data or any derivative dataset without verifying the license of the data, or without obtaining a written permission from the copyright holder.
If you doubt on the legality of what you’re doing, don’t do it. Or seek the advice of a lawyer.
Don’t base your whole business on data scraping. The website(s) that you scrape may eventually block you, just like what happened in Craigslist Inc. v. 3Taps Inc..
Finally, you should be suspicious of any advice that you find on the internet (including mine), so please consult a lawyer.
Body jsou převzaty z “Příklady soudů a mýtů kolem legální nelegální”
5. Soubor robots.txt
S jakými pravidly se můžete setkat v tomto souboru
A. Povolen plný přístup
Můžete přistupovat ke všem stránkám na webu pomocí robota, bota, stroje. Plný přístup poznáte tak, že bude v souboru uvedeno:
User-agent: *
Disallow:
B. Blokování všech přístupů
Na takové stránce není dovoleno strojově proházet data.
V souboru bude uvedeno:
User-agent: *
Disallow: /
C. Částečný přístup
Na takovém webu můžete strojově procházet pouze stránky na webu, které nejsou v souboru definovány jako zakázané např.:
robots.txt
User-agent: *
Disallow: /some_folder/
robots.txt
User-agent: *
Disallow: /register.hmtl/
D. Limit frekvence prolézání webu (Crawl rate limit)
Doba mezi jednotlivými požadavky. Nemůžeme poslat několik požadavků najednou, ale vždy jen jeden a potom musí být časová pauza. V uvedeném příkladě je nutné nastavit frekvenci požadavku jednou za 11 sekund, vždy lze nastavit pouze doba mezi jednotlivými requesty:
robots.txt
....
....
Crawl-delay: 11
E. Určený čas pro scrap a crawl (Visit time)
Časové okno, kdy je dovoleno provádět strojové procházení stránek. Obvykle bývá nastaveno mimo špičky provozu. Uvedený příklad říká, že je možné dělat web scraping v časovém oknu 06:00 - 08:30 UTC.
robots.txt
....
....
Visit-time: 0600-0830
F. Frekvence požadavků (Request rate)
Je počet requestů za časovou jednotku například 15/1m znamená, že můžeme poslat 15 requestů najednou za a pak čekáme do konce uplynutí jedné minuty, tedy neděláme nic, pak pošleme dalších 15 requestů. Některé stránky dovolují načítat několik stránek najednou. A požadují nastavení frekvenci requestů. Uvedený příklad požaduje nastavení maximálně 2 requesty za 10 sekund.
robots.txt
....
....
Request-rate: 2/10
Použité zdroje - další studium
Beautiful soup:
Python nástroje pro web scraping - srovnání:
Je to vůbec legální ?: